作者|Moonshot
编辑|靖宇
9 月 26 日飓风「海伦妮」从佛罗里达州登陆美国,袭击美国南部多州多地,至今已造成超过 230 人死亡,「海伦妮」也已经成为 2005 年「卡特里娜」飓风以来,导致美国本土死亡人数最多的飓风。
与此同时,一张 AI 生成的照片,也在社交媒体上掀起轩然大波,甚至在下个月选举来临之前,引发了两党的「红蓝对决」。
到底是什么图片,能比飓风带来的影响更严重?
飓风营救 or 非洲秃鹫
共和党全国委员会的委员、Women for Trump 的联合创始人Amy Kremer 发在 X 上推文「这张照片深入脑海,令我心痛」,配图是一个楚楚可怜的小女孩,身着救生衣,在救生艇上眼中含泪抱着一只小狗。

这类聚焦在单一受害者,无辜的女童不得不躲避灾祸的照片,都非常容易调动起人们的同情心,就像那张《饥饿的苏丹》,瘦骨嶙峋的小女孩背后是一只紧盯着她的秃鹰,越战中躲避燃烧弹的《凝固汽油弹女孩》激起过无数年轻人的反战情绪,那张学习中的「大眼女孩」也让希望工程深入人心。因此这张「飓风中紧抱小狗的女孩」照片也在社交媒体上被大量转发。
但在情绪过后仔细再看,小女孩的手臂和腿部极度光滑且和肤色不符,头发也呈现非常奇怪的纹理,大拇指骨节也呈现怪状凸起。没错,这张照片是一张 AI 生成的图片。

这张 AI 痕迹更浓了,但不妨碍收获百万级观看量|图片来源:X
在被评论区的人指出「假图」之后,Kremer 直接发文开怼称「是啊,我是不知道这张照片是从哪来的,说老实话,哪儿来的无所谓。它已经永远烙印在我的脑海中了,有些人比这张照片所显示的经历还要糟糕得多。它象征着人们现在正在经历的创伤和痛苦。」换言之,她知道这张图片是假的,但她不在乎,因为她的目的不在于同情这位「AI 女孩」,而是攻击执政党应对「海伦妮」飓风的失责。
因为类似的 AI 照片也被极右翼政客Laura Loomer、共和党 KOL 及特朗普支持者Buzz Patterson和Juanita Broaddrick 转发,配文则是「我们的政府又让我们失望了」或「执政者抛弃了他们」。这些推文的传播量均已上百万。

传播只为甩锅|图片来源:X
AI 假图片已经成了党派之间相互掣肘的政治工具,伴随着这张照片一同传播的还有各种阴谋论和假新闻,诸如「联邦紧急事务管理局正在准备把灾民财产充公」「当局在控制共和党支持州(飓风受灾州多为支持共和党的(红州)天气」。
相应的,Facebook 上也流传着特朗普冒着洪水帮助居民的图片,当然也是 AI 合成的。该帖子在两天内被分享了超过 16 万次。

图片来源:PolitiFact
特朗普本人也在前不久泰勒·斯威夫特公开表态支持民主党总统候选人哈里斯后,在自己的 X 上发布了「Swifties for Trump」(支持特朗普的泰勒粉丝),附上的图片全是 AI 生成的假图。
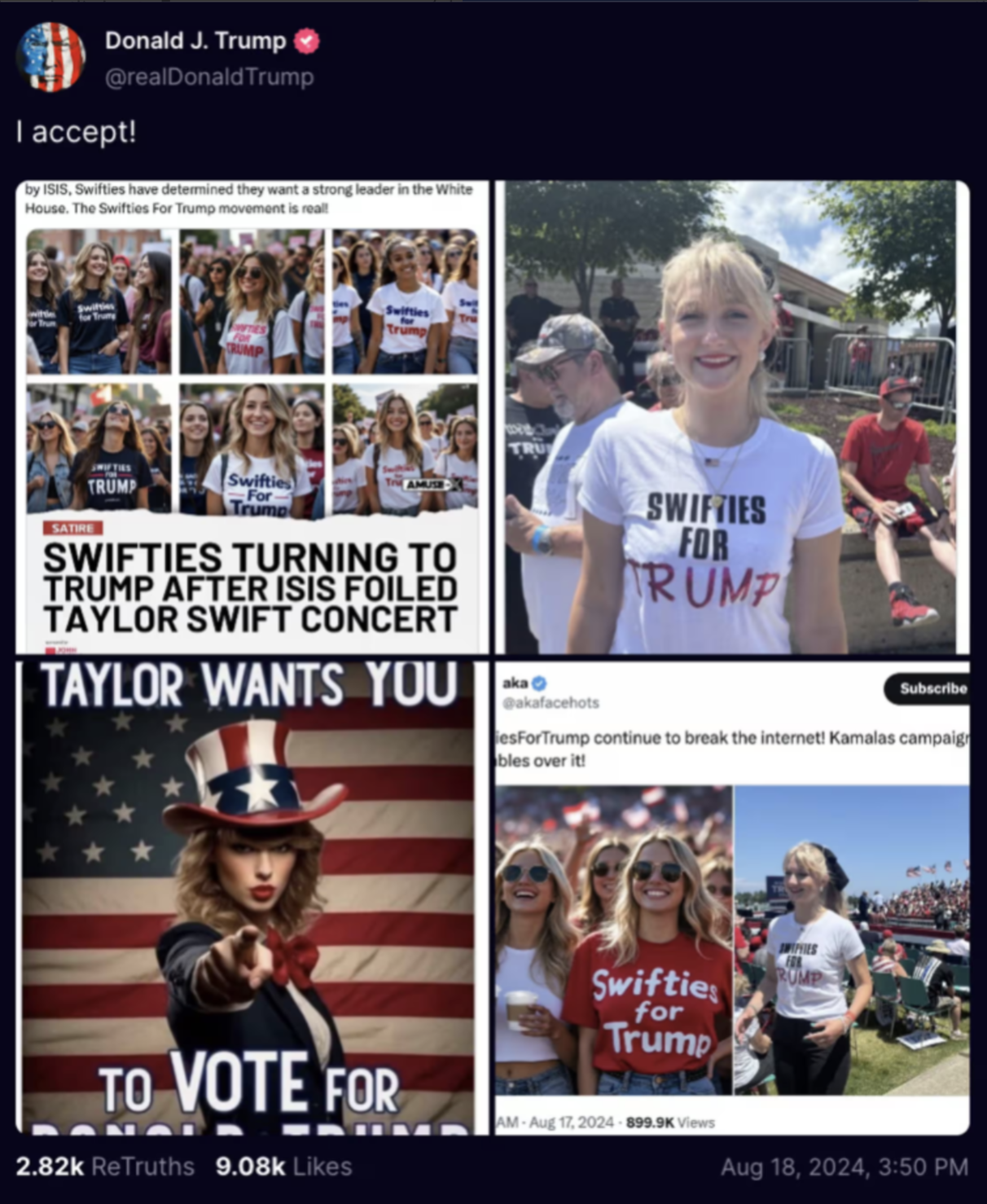
图片来源:X
这并不是特朗普第一次发 AI 假图,作为马斯克支持的候选人,特朗普不可能没有分辨 AI 内容的能力,毕竟不久前他还发布了他和马斯克一起跳舞的 DeepFake AI 合成视频。
但在碎片化的社交媒体平台,政客们不在意信息真假,不管是实拍还是 AI 生成的照片,只要有传播效力即可,造势才是社交平台上政治宣传的首要目的,感性的印象取代客观事实,「造谣一张嘴,辟谣跑断腿」的传播学原理在 AI 时代更猛烈地回响着。
谁在制造 AI 垃圾
但追根溯源,这些 AI 假内容是谁生成的,又怎么在各种社交媒体上广泛传播,能骗一个是一个的呢?
这张图加配文「亲手制作,谢谢大家的喜欢」在 Facebook 上收获了 87 万点赞,3.5 万的评论,然而它是 AI 生成的一张假图片。
而喂给 AI 的原图,则是一个木雕艺术家 Michael Jones 和他创作真实存在的木雕狗,Jones 的原帖只获得了 1063 个赞,110 条评论,与 AI 假帖相去甚远。

同时,在 Facebook 上还流传着不同种族、性别、狗的品种的类似图片,它们的来源都是 Jones 的这张图,这意味着任何人都可以每小时用 AI 创造上百张以假乱真的图像,然后在社交平台上随即发布,总有几条能斩获不错的流量和曝光。其中,Facebook 是重灾区。
去年底,科技网站 404 Media 的记者就发现,Meta 旗下的 Facebook 上明显是 AI 生成内容的帖子数量激增,同时也扩散到Meta 旗下的 Threads。

Facebook 这种「一眼假」的图片数据都惊人的好|图片来源:Facebook
为什么 Facebook 是重灾区?原因很简单:平台算法化赶上了用户老龄化。
在最近的一次财报电话会议上,Meta CEO 扎克伯格告诉分析师,为了跟上 TikTok 等平台的变化,Facebook 向用户算法推荐的帖子数量翻了一倍,推荐帖子现在约占用户主页的 30%。
然而据 OBERLO 调查机构的数据显示,Facebook 25 岁以上用户占比达到 77.4%,其中 35 岁用户以上占比达到 46.6%。对于大量出生在前互联网时代,可能在中年才开始使用社交媒体和智能手机的中老年人来说,理解 AI 是什么都费劲,更别提鉴别 AI 内容了。

8 月由斯坦福互联网实验室发布的论文《垃圾内容和骗子如何在 Facebook 上利用人工智能生成的图像来增加受众》也在测试中发现,他们用 AI 生成的图像总共获得了数亿次曝光。AI 生成的图文帖通常是标题党配合夺人眼球的图片,比如一个断腿的小孩子举着牌子说「祝我生日快乐」就能收获 7 万点赞和 3000 条评论。用户的评论也能显示出他们并没有意识图片是由 AI 生成。
而且算法推荐就像一个上升的螺旋,研究者发现,在点进几个 AI 生成内容帖后,哪怕没有关注和点赞,后续自己的主页也会推送越来越多的 AI 帖。已经有一些活人用户在 Reddit 上辣评「Facebook 已经变成刷不完的 Midjourney AI 照片墙了。」

一眼 AI 但能收获大量流量|图片来源:404
骗流量之外,AI 假图片还想骗钱,比如就像上面显示的木雕狗,可能帖子里就会附赠「购买同款木制品」的链接,实际上并不存在这些产品,又或者会把观众引流到其他广告网站,像上面最火的木雕狗帖,点开评论区就发现置顶了一条宠物用品的销售链接。
更吊诡之处在于,许多照片可能正是用 Meta AI 所生成,Meta AI 的目的之一就是让照片以假乱真,然而这些照片骗过了自己的用户,矛盾至此转换成了流量的循环。
AI 生成垃圾内容影响的不仅是「老龄化」的 Facebook,就连曾经以高质量文本内容出名的「美版知乎」Quora,都不得不面对 AI 生成内容去稀释社区内容质量的现状。
更糟糕之处也在于,现在许多 AI 生成图片正在和现实牢牢捆绑在一起,就比如海伦妮飓风尚未平息,但在 AI 假图被识破后,每个用户都会质疑每一张照片的真实性,哪怕它是基于现实的实拍照片,在经过大量假内容稀释后,都要面临「真假美猴王」自证清白的窘境。
巴以冲突、美国大选、巴西洪水、海伦妮飓风……这些现实生活中真实发生的天灾人祸,在碎片化、简介信息、图文为主且注重高度时效性的内容社区来上,战地记者的实拍图收到的浏览量可能远比不过 AI 生成的假图片。
而这些内容往往都针对毫无戒心的老年人,他们基于同情心,贡献了自己的点赞和转发,不知不觉中却成了算法的帮凶。而这些 AI 的养料则是基于原创但不被看见的艺术家。
而作为具有重要责任的社交平台,例如 Meta,则陷入了 AI 的自我「矛盾之战」:用户使用 Meta 的 AI 工具生产出虚假信息和垃圾信息,将其发布到 Meta 平台,而 Meta 的 AI 团队则需要通过技术鉴别到底哪些是真实图片,哪些是 AI 生成的。
其中的讽刺耐人寻味——AI生成技术团队越进步,审核和鉴别团队就越难做。
在垃圾信息已经充斥互联网的当下,AI 生成工具的诞生,无疑再次为网络垃圾化的进行提供了加速度。如果无法解决这个挑战,被「困在系统中」的不仅仅是用户,后者平台,而是所有人。