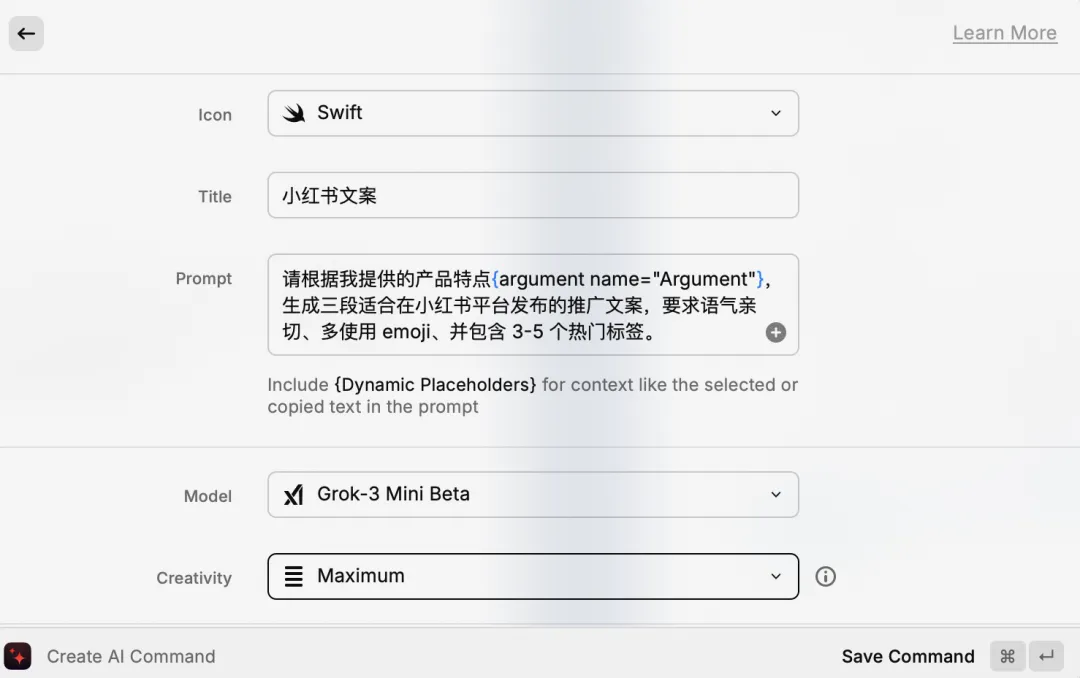
苹果考虑收购初创公司 Perplexity,以补齐 AI「短板」
彭博社记者马克・古尔曼今天清晨撰文称,苹果公司正考虑收购 AI 初创企业 Perplexity AI,以补强公司在 AI 领域的人才和技术储备。
在稍早前的本周五,苹果公司遭到股东集体起诉,被指在信息披露中低估了将先进生成式 AI 整合进语音助手 Siri 所需的时间,导致 iPhone 销量受影响、股价下滑,构成证券欺诈。
据知情人士透露,苹果并购负责人艾德里安・佩里卡已与服务部门主管及 AI 战略高层就此展开内部讨论。目前谈判尚属初步阶段,未来未必会提出正式收购要约。
Perplexity 提供基于网络实时信息的问答服务。Perplexity 最近完成融资,估值达 140 亿美元。若交易按此估值进行,将超越苹果此前收购 Beats 创下的纪录,成为苹果历史上最大的一笔并购。
若成功收购 Perplexity,苹果不仅将获得一支 AI 技术团队,还能借助其在业内的知名度以及成熟的消费者产品,有助于后续人才引进。(来源:IT 之家)

多多买菜即将上线即时配送服务
据《晚点 LatePost》获悉,多多买菜正在上海等一线城市试验自建商品仓库,最快将于 8 月上线即时配送服务,以类似京东秒送、淘宝闪购的速度送商品上门。不过,不同于京东、淘宝的大举投入,多多买菜的尝试还在早期阶段,并且也不会涉足餐饮外卖。
拼多多表示,这不能代表公司战略和方向,称其无意加入即时零售大战。
一位接近多多买菜的人士说,他们担心美团闪购的崛起会影响多多买菜,如果继续增长,未来还可能会冲击拼多多主站以米面粮油为主的类目。(来源:晚点)
华为开发者大会,发布鸿蒙 6.0 Beta 及多个模型
6 月 21 日,华为开发者大会在东莞松山湖举行。在大会现场,华为发布了 HarmonyOS、盘古大模型等方面最新进展。
HarmonyOS 6 将带来全新的互联和智能体验,全场景体验更易用,时延低达毫秒级;鸿蒙智能再进化,AI 能力更开放。
盘古大模型 5.5 正式发布,在自然语言处理,多模态等 5 大基础模型全面升级。包括 MoE 7180 亿参数的深度思考模型、基于盘古多模态大模型的世界模型、300 亿参数 MoE 架构的盘古视觉大模型。
同时,华为也发布了 CloudRobo 具身智能平台。他强调,华为云不做机器人本体,把机器人本体交给伙伴。华为云的目标是让一切联网的本体都成为具身智能机器人。(来源:财联社)

稳定币第一股上市两周涨幅超 640%
6 月 20 日,Circle 股价开盘大涨 16%,上市以来累涨超 640%。
当地时间 6 月 5 日,Circle 正式在纽交所上市。作为全球第二大稳定币发行商,Circle 的核心竞争力源于 USDC 的生态渗透力。招股书显示,截至 2025 年 4 月,USDC 流通量高达 601 亿美元,在稳定币市场占据约 29% 的份额,仅次于 Tether 发行的 USDT。(来源:每日经济新闻)
饿了么前CEO被警方带走,涉嫌职务犯罪
近日,饿了么物流负责人、原 CEO 韩鎏在上海办公室被警方带走。据财新了解,初步原因是涉及供应链利益输送。
对于韩鎏被调查一事,饿了么方面回应称:通过内部调查发现物流主管韩鎏涉嫌职务犯罪,并向警方主动报案。近日,警方已传唤相关人员配合调查。饿了么秉持诚信廉洁文化,对触碰红线行为绝不姑息,坚决依法依规处理。
韩鎏早年任职于京东商城和京东物流,2019 年加入阿里巴巴,花名昊宸。2024 年 3 月,韩鎏升任饿了么 CEO。两位了解韩鎏的人士指出,韩鎏在不同公司任职期间都被疑向下游供应链利益输送问题。(来源:财新)
传宇树科技正积极推动 IPO,投资人:首选 A 股
宇树科技于近期完成了 C 轮融资,由移动旗下基金、腾讯、锦秋、阿里、蚂蚁、吉利资本共同投资。知情人士透露,此轮融资募资规模约 7 亿元人民币,融后宇树科技估值达到约 120 亿元人民币。此次融资或将是宇树 IPO 前最后一轮融资,上市前再融资的可能性较小。
据悉,目前宇树科技公司和投资人都在积极推进 IPO 事宜,首选在 A 股上市,其次是香港。(来源:钛媒体)

微信朋友圈推出回复带图功能,正灰度测试
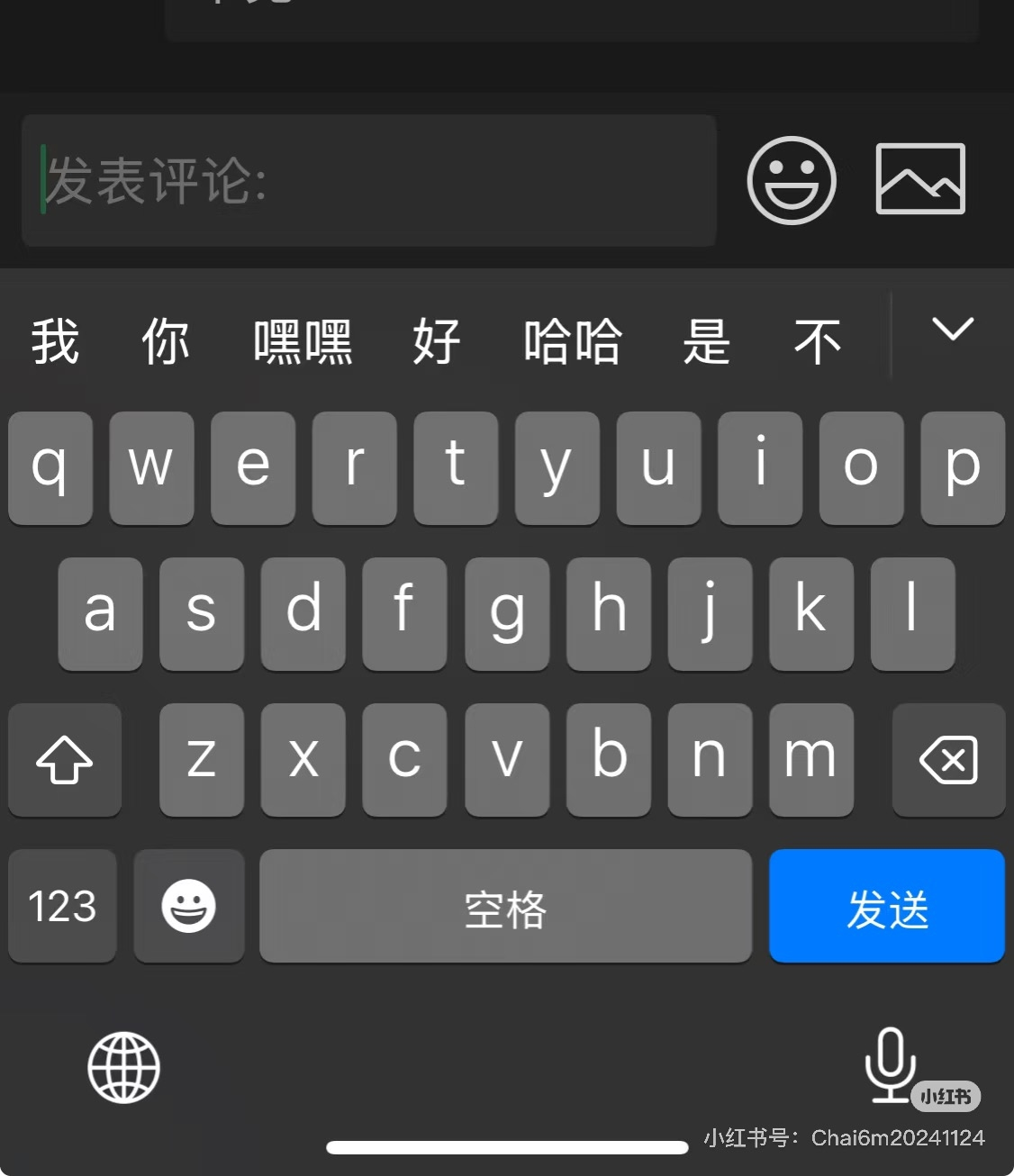
日前,有网友在社交平台表示,微信朋友圈的评论可以发表情包和图片了。腾讯客服对此表示,微信更新至 8.0.60 版本后,朋友圈支持在评论中添加表情包或从相册上传图片。该功能目前处于小范围内测阶段。
此前,微信在 2019 年曾推出过支持朋友圈评论用表情包回复的功能,但该功能很快便被下线。(来源:快科技)
Meta 联合 Oakley 推出新款智能眼镜,399美元起步

6 月 20 日,Meta 与依视路合作推出了一款全新的 Oakley Meta HSTN 智能眼镜,起售价 399 美元(当前折合人民币约 2868 元),限量版 499 美元。和此前畅销的 Ray-Ban Meta 相比,新产品起售价贵了 100 美元,电池续航时间是之前的两倍。
这款眼镜采用最先进的 Oakley PRIZM 镜片,结合 Oakley 的 PRIZM Lens 技术,旨在帮助运动员在不断变化的光线和天气条件下获得更清晰的视野。
据介绍,Oakley Meta HSTN 常规使用状态下续航时间可达 8 小时,待机续航时间长达 19 小时;并且支持快充,只需 20 分钟即可充至 50%。它还配备了类似耳机的充电盒,综合续航 48 小时。
Oakley Meta HSTN 采用了更高分辨率的 3K 摄像头,支持 IPX4 防水,沿用 Ray-Ban 眼镜的核心功能,例如集成开放式扬声器、内置双麦克风,还有 Meta AI 个人助手。(来源:IT 之家)
史上最大尺寸双折叠,三星 Galaxy Z Fold7 渲染图出炉

近日,三星 Galaxy Z Flip7 的外观渲染图在社交平台上被曝光。这是行业内最强悍的小折叠屏,新品将于 7 月发布。
对比上代,Galaxy Z Fold7 变化最大的是重量和尺寸。Galaxy Z Fold7 重量降至 215g,比上代轻了 24g;内屏尺寸增大至 8.2 英寸。这是史上尺寸最大的双折叠,竞品谷歌 Pixel 9 Pro Fold 的尺寸是 8 英寸、OPPO Find N5 尺寸是 8.12 英寸,外屏尺寸预计是 6.5 英寸。
另外,三星 Galaxy Z Fold7 至少提供黑色和蓝色两种配色,镜头 DECO 跟三星 Galaxy S25 系列接近,搭载高通骁龙 8 至尊版平台,电池是 4400mAh。
值得注意的是,爆料称三星砍掉了 Galaxy Z Fold7 的屏下摄像头方案,转而采用传统的挖孔屏,原因是屏下摄像头技术会影响到成像。而去年发布的 Galaxy Z Fold6 配备 400 万像素屏下摄像头。(来源:cnBeta)

罗马仕充电宝 3C 认证被撤销,快递公司拒收其召回产品
6 月 20 日,国家市场监管总局全国认证认可信息公共服务平台显示,深圳罗马仕科技有限公司及相关公司的快充移动电源 3C 认证被大批撤销,证书状态显示「暂停」,剩余 3C 认证基本都与充电器和插座相关,仅剩江门罗马仕科技有限公司一项「快充移动电源」的证书状态仍为「有效」。
关于召回原因,罗马仕称,本次召回的移动电源产品,由于部分电芯原材料来料原因,极少数产品在使用过程中可能存在过热现象,在极端场景下可能产生燃烧风险,存在安全隐患。
据网友分享,在联系罗马仕在线客服后需要提交信息和排队,客服确认信息后则会提供地址,用户将问题移动电源通过快递寄送给罗马仕。
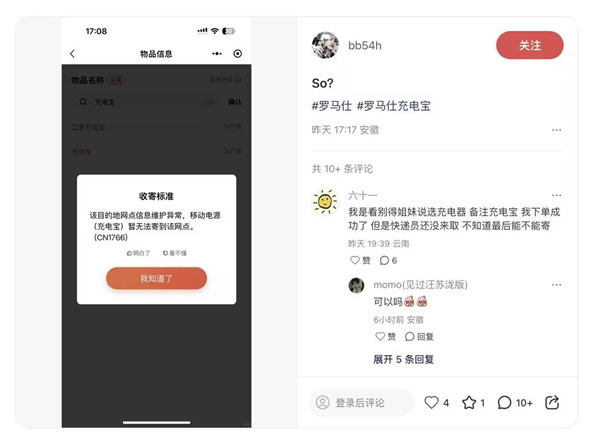
目前部分用户已经通过快递将移动电源寄回广东江门的售后服务地址,不过一些快递公司的部分网点,疑似因为存在安全风险的原因,开始拒收发往广东江门的罗马仕品牌移动电源。(来源:澎湃新闻、快科技)